Monitoring Production ML Model Inputs Practically and Efficiently in the Absence of Ground Truth Data
In real life ML monitoring applications, we want to detect whether or not a ML model is performing well or is breaking. Not picking up on poor model performance can translate into poor or even biased predictions that can lead to lost revenue and even PR fires that we see year over year from even the large tech companies, from facial recognition systems that fail to pick up on certain minorities to hate speech in autocomplete for search engines.
In this article, we’ll go over a brief overview of how data drift thresholding helps capture poor model performance, and the majority of the post will focus on two versions of implementing automated data drift detection in production level ML monitoring systems.
Overview
Why do we need data drift?
The standard approach to monitoring models is based on performance metrics, i.e. accuracy/precision/recall/f-score, over some time period or from batch to batch. In order to produce these metrics, we need both predictions and ground truth labels for the datapoints, e.g. a credit risk model predicts that a person will pay their loan on time in 1 year and thus should be approved for a credit card, and we know whether or not that person paid their loan on time in 1 year. Already, we have an issue because we do not know ground truth until 1 year later.
In most production applications, there is a lag between prediction time and ground truth collection time, which significantly handicaps the ability to remediate model issues quickly. Leveraging labeling teams or services can help close this lag, but it will not completely remove it. As such, instead of monitoring metrics based on outputs, we can instead monitor inputs based on data drift metrics.
What is data drift?
Data drift fundamentally measures the change in statistical distribution between two distributions, usually the same feature but at different points in time. As an example, in the univariate case where we’re looking at one input feature, we should reasonably expect that, if the shape of the feature shifts significantly between training time and prediction time, the model outputs will degrade in quality.
As a toy example, if we train a ML model to solve math problems only on algebra questions, and all of a sudden geometry questions are fed into the model at prediction time, we’d expect the predictions to be pretty bad since the model hasn’t been trained on geometry questions.
In essence, data drift is a proxy for our classical performance metrics in the absence of ground truth labels. The next natural question is how to formally quantify data drift.
Overview of data drift metrics
There are many different kinds of metrics we could use for quantifying data drift. Here, we’ll focus on two popular families of metrics: f-divergence and hypothesis test metrics. For the former, we’ll look at KL Divergence and PSI. For the latter, we’ll look at Chi-Squared and KS test statistics.
For any drift metrics, P is the training data (reference set) on which the ML model was trained and Qis the data on which the model is performing predictions (inference set), which can be defined on a rolling time window for streaming models or a batch basis for batch models.
KL Divergence
If you need a quick overview, I’ve found this introductory post very helpful.
KL Divergence from P to Q is interpreted as the nats of information we expect to lose in using Q instead of P for modeling data X, discretized over probability space K. KL Divergence is not symmetrical, i.e. the value is different if P and Q are swapped, and should not be used as a distance metric.
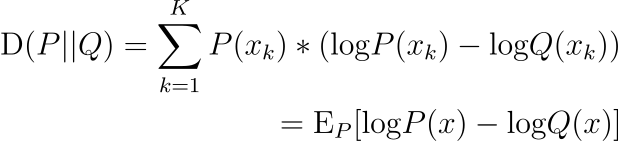
Population Stability Index (PSI)
While KL Divergence is well-known, it’s usually used as a regularizing penalty term in generative models like VAEs. A more appropriate metric that can be used as a distance metric is Population Stability Index (PSI), which measures the roundtrip loss of nats of information we expect to lose from P to Q and then from Q returning back to P.
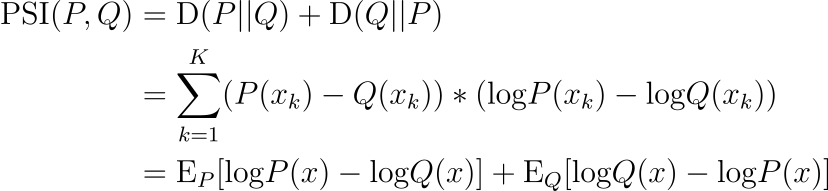
Hypothesis Tests
Hypothesis testing uses different tests depending on whether a feature is categorical or continuous.
For a categorical feature with K categories, i.e. K−1 are the degrees of freedom, where N_Pk and N_Qk are the count of occurrences of the feature being k, with 1≤k≤K, for P and Q respectively, then the Chi-Squared test statistic is the summation of the standardized squared differences of expected counts between P and Q.
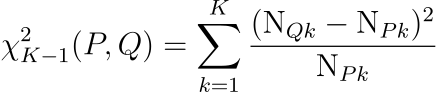
For a continuous features with F_P and F_Q being the empirical cumulative densities, for P and Q respectively, the Kolmogorov-Smirnov (KS) test is a nonparametric, i.e. distribution-free, test that compares the empirical cumulative density functions F_P and F_Q.
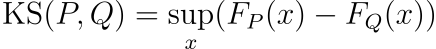
Why Automated Drift Thresholds?

Having humans manually look at drift metrics produced by a model over time or over batches is obviously tedious and not ideal, and the immediate use case for drift metrics would be to set alerts based on some threshold, e.g. PSI jumps over .3 for this batch and should create an alert for a person to examine. Remediation actions could be checking if a pipeline that’s feeding that feature into the model is broken, if there was a recent buggy code or calculation change, or if the feature really did drift and suggests that the model needs to be retrained.
But where did that .3 come from? Setting arbitrary handpicked thresholds is not a good solution. If the threshold is too high, alerts that should be brought up are now ignored (more false negatives). If the threshold is too low, alerts that should not be brought up are now present (more false positives).
A universal constant threshold is not robust because that threshold should depend on the shape of the the training data P. If P is uniform and we see a unimodal Q, that drift value is going to be significantly less than if P was highly unimodal and centered at some mean far away from that same Q, since the former P that is uniform is less certain if Q did not come from P. An example is shown below.
https://medium.com/media/a97f8be159b205ece1056f4e516c1aa3/href
In order to set robust thresholds that make sense for an alerting system, we’ll dive into how to automate calculation of such thresholds. That is, we want to recommend data drift thresholds to create alerts, so users (a) don’t have to manually set alerts and (b) don’t have to determine what a good threshold value is.
Automated Drift Thresholds for Hypothesis Test Metrics
For hypothesis test metrics, the trivial solution would be setting thresholds at the the proper critical values for each test using the traditional α=.05, i.e. 95% confident that any hypothesis metric above the respective critical value suggests significant drift where Q ∼ P is likely false.
Hypothesis tests, however, come with limitations, from sample sizes influencing significance for the Chi-Squared test to sensitivity in the center of the distribution rather than the tails for the KS test.
For those reasons, it’s important to explore other classes of drift metrics such as f-divergence metrics, and we’ll now explore ways to automate f-divergence drift thresholds.
Automated Drift Thresholds V1: MC Simulation
Overview
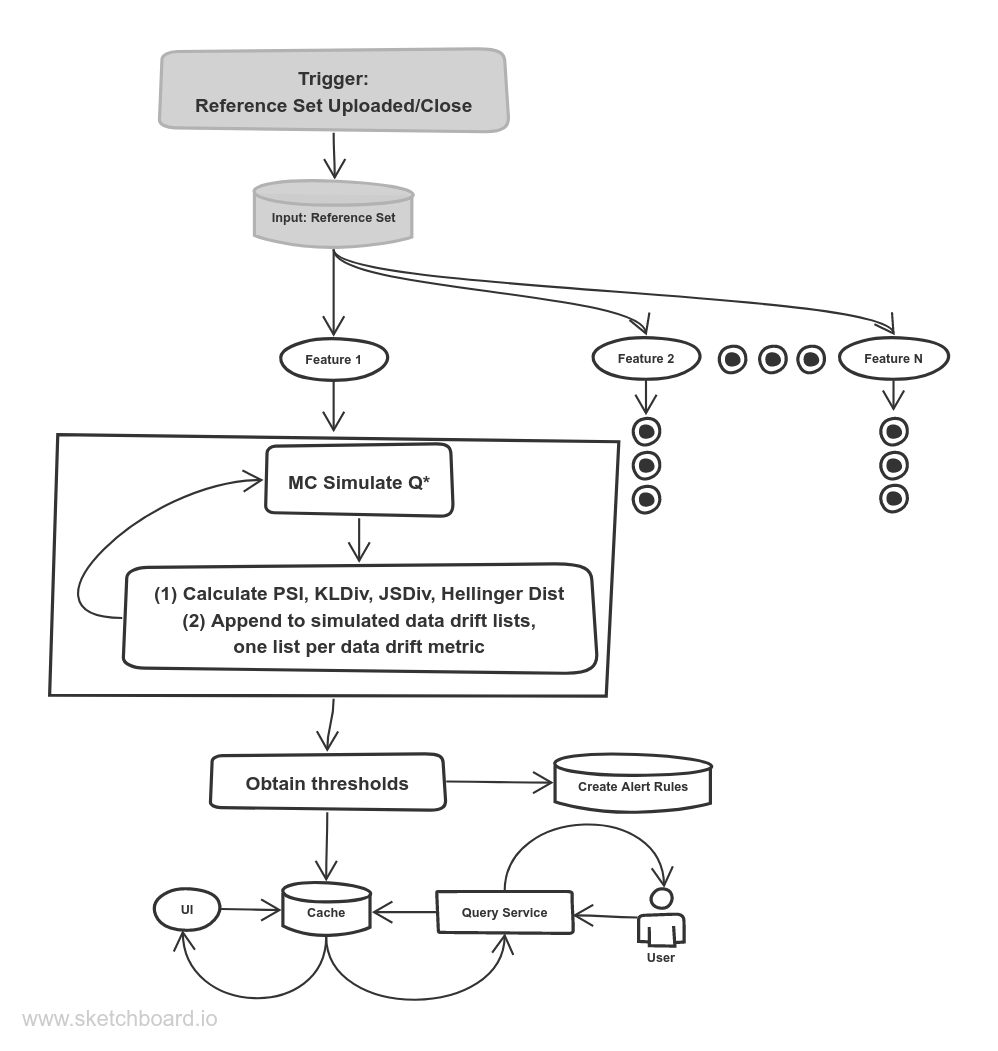
(1) For a large number of simulations indexed by i, for a given input feature, MC (Monte Carlo) simulate m times, where m is sufficiently large, from the reference set P and construct an inference distribution Qᵢ*, which represents what we’d expect had our data truly come from P via simulation. Then we calculate and keep track of data drift f(P, Qᵢ*) for each simulation.
(2) We set the data drift threshold to the conservative value of max_i(f(P, Qᵢ*)), which is essentially a critical value/cutoff where α → 0 in a traditional statistics setting, i.e. we are 99.999% confident that a data drift value from an actual Q, i.e.inference time slice or batch, that is above the threshold signifies that the inference data was not produced from the same underlying distribution as P. If incurring false positives is not expensive, then we could set the threshold instead to the 95% percentile of f(P, Qᵢ*) in the traditional α=.05 one-sided setting.
Limitations of MC Simulation
MC methods are attractive because they are simulation-based and distribution-free, but this method is not scalable due to two issues.
(1) Running simulations for every feature per model is computationally expensive. Specifically, runtime on a per model basis would be O(n_features*n_categories_per_feature*n_metrics*n_simulations).
(2) The assumption of sampling stability is broken with lower sample sizes.
As a toy example, let’s say we have red, white, blue, and orange marbles in P, distributed uniformly. Let’s now present Q of size 3; there is no way to tell if the Q came from P or not since there is no way for us to represent all four colors. Even if we had sampled 6 marbles, we could not closely approximate 1/4 for each category given those 6 marbles.
Let m be the number of simulated datapoints on each simulation to create Qᵢ*. In the same toy example of marbles, sampling instability causes artificially high uncertainty(and therefore artificially high data drift thresholds) when m is low, as P has not been well MC-sampled and represented in Qᵢ*.
https://medium.com/media/1da09d6ebabb2cf41ba081d46da464d5/href
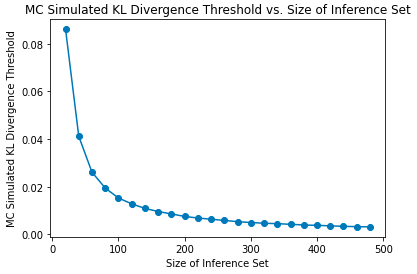
The way to fix issue (2) is to create simulated threshold curves for a given feature by varying m, but now we have exacerbated issue (1) by multiplying runtime by m. We also now have issues with space complexity, since now we would have to store thresholds in a lookup (database or cache) for use in downstream applications, like an alert service creating alert rules or a query service cache. Forgoing the extra storage and simulating the threshold curve at query time is also not an option since the query would take too long for most user-facing applications.
In short, the trade-off of using a flexible simulation setup is not worth the computational expenses when taking into account correction curves that would either (a) need to be stored, which would cost a lot in storage fees or blow up a cache, or (b) be simulated at query time, which is too slow for user-facing applications.
Automated Drift Thresholds V2: Closed-Form Statistics

It turns out that we can upper bound data drift thresholds in one shot using probability theory. We’ll make use of standard probability theory, the Dirichlet distribution, and first-order Taylor series expansions. Remember that we are still deriving the thresholds on a per feature basis.
KL Divergence
First, let
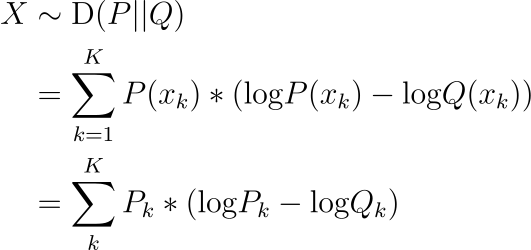
Reference set P is known and inference set Q is unknown. Intuitively, this simply means that we have observed the training data used in creating our ML model and that we’re asking a hypothetical question of what we could expect data drift to be for some hypothetical inference set Q in the future. Formally,
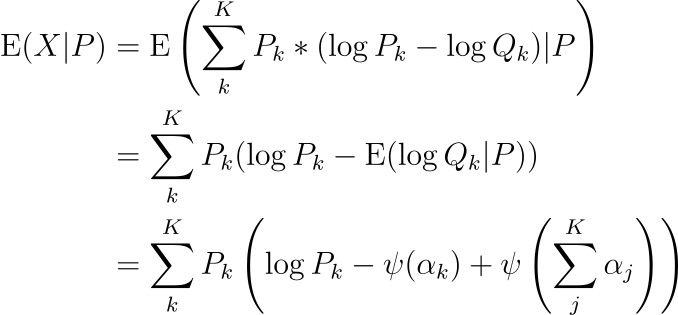
2nd line: Linearity of expectation and conditional probability.
3rd line: Q ∼ Dirchlet(α), i.e. Q models a probability distribution and is a multivariate generalization of the beta distribution. As such, we can use the digamma ψ function in this case.
α = (α_1, …, α_K) traditionally corresponds to the observed probabilities in the K categories for the feature from Q, offset by a small constant, i.e. prior counts. However, Q is unknown, so how do we derive the correct counts? We do so from P. After all, the entire point of this expectation statement is to quantify on average the drift we’d expect to see if Q ∼ P, and an amount above that value in an actual inference set signifies that we likely have significant drift, i.e. Q ∼ P is false.
Back to α, we can use a Bayesian uniform prior Q ∼ Dirichlet(1_K) and update such that Q|P ∼ Dirichlet(1_K + N_q * p_K), where N_q is the number of datapoints in the inference set Q and p_K corresponds to the known K-dimensional probability vector for the feature from P. This is the multivariate generalization of the the beta-binomial conjugacy.
So we thus have,
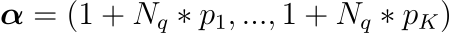
Population Stability Index
PSI gets a bit more tricky and we need to upper-bound the expectation. Let
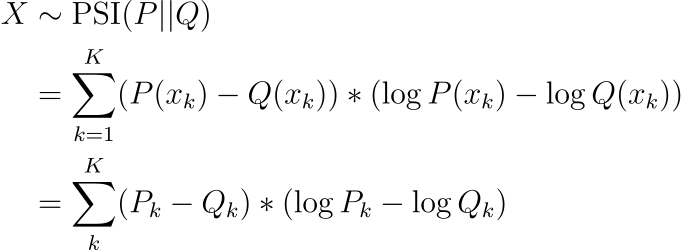
Then
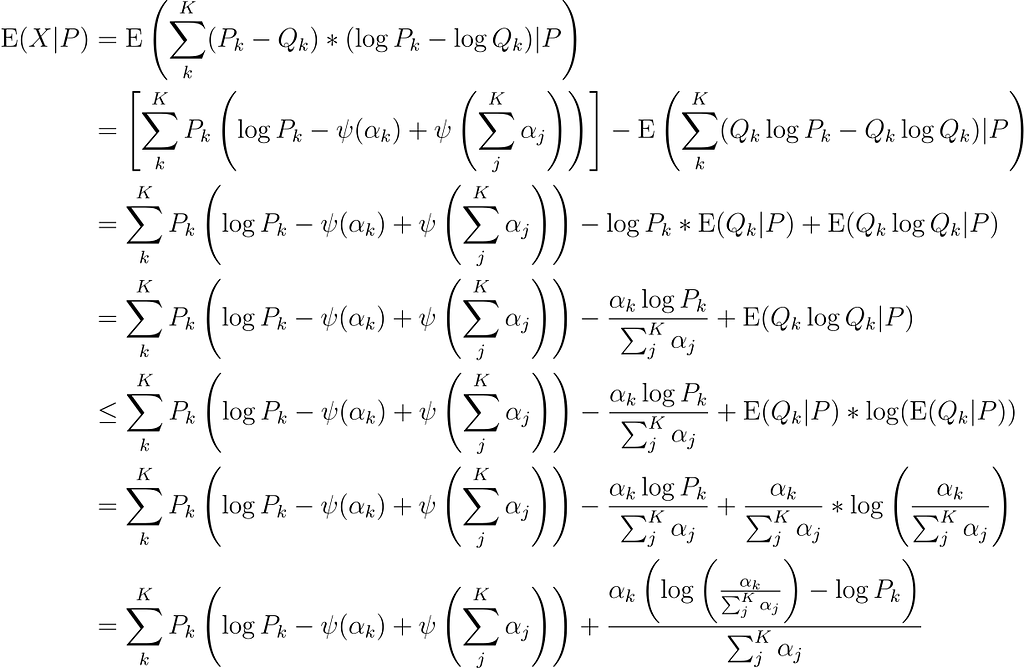
Here are the steps:
2nd line: Linearity of expectation and substituting the result for KL Divergence above.
3rd line: Linearity of expectation and conditional probability.
4th line: Expectation of a Dirichlet distribution.
5th line: Delta method approximation (see appendix).
6th line: Expectation of a Dirichlet distribution.
7th line: Simplifying.
V1 Issues Solved!
Notice how we now have solved for the two issues from MC simulation.
(1) We do not have to worry about runtime, as this form is a one shot solution that only involves counts and we can use an approximation to the digamma function.
(2) We handle varying sample sizes by using a Bayesian plus pseudocount setup on the parameters of Q.
Implementation
In production, how do we implement this dynamic thresholding? Although the thresholds are dynamic depending on the metric and the incoming inference set, all of the expectations above, conditioned on P, can be expressed as SQL queries or custom but simple functions.
Discretizing all continuous features, instead of smoothing discrete features, would be a reasonable trade-off: although we may not capture the full continuous nature of P and Q, we’ll avoid computationally expensive kernel density estimation in representing P and Q as continuous distributions.
Wait, what about variance?
We can calculate variances too and apply Delta method approximations, as we would run into variances and covariances on logarithmic terms that cannot be solved using standard probability theory. Those tools are below in the appendix. However, as it turns out, most metrics will not come out as cleanly as KL Divergence, so most of the conditional expectations and variances are upper-bounded via Cauchy-Schwarz. It’s certainly doable to include an additive upper-bounded variance term, or to even use second-order approximations, but the extra computation might not be worth the time gained in exchange for a stricter bound.
For another time…
We can also use Taylor series expansions to upper-bound other metrics, like JS Divergence and Hellinger Distance.
Conclusion
That’s it for today! Hope you gained some insights about how to implement automated thresholds in a computationally and probabilistically sound manner! We implement these kinds of systems at Arthur AI, and a few equations can go a long way for the customer experience.
Happy monitoring!

Appendix: Delta Method Approximations
Note that the first-order approximations for both sections below are upper bounds because the log function is concave.
log(X) Approximation
By a first-order Taylor series expansion around the mean,
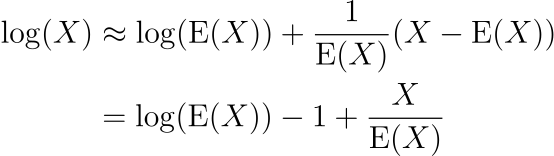
Using this approximation, we have
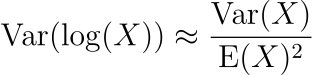
and
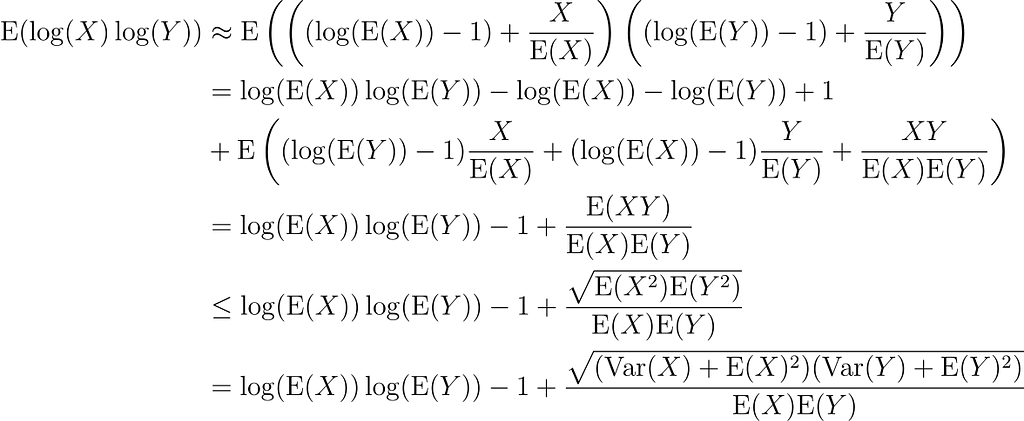
with inequality by Cauchy-Schwarz.
Xlog(X)
By a first-order Taylor series expansion around the mean,
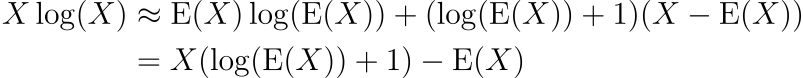
Using this approximation, we have
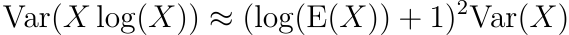
and letting
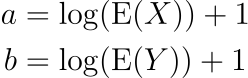
we have
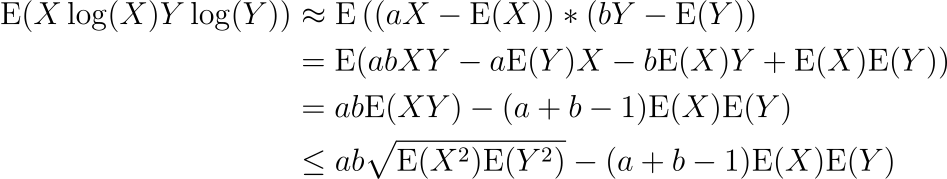
with inequality by Cauchy-Schwarz.
Automating Data Drift Thresholding in Machine Learning Systems was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content was originally published here.
