To better understand the landscape of available tools for machine learning production, I decided to look up every AI/ML tool I could find. The resources I used include:
- Various lists of top AI startups by the media
- Responses to my tweet and LinkedIn post
- People (friends, strangers, VCs) share with me their lists
After filtering out applications companies (e.g. companies that use ML to provide business analytics), tools that aren’t being actively developed, and tools that nobody uses, I got 202 tools. See the full list. Please let me know if there are tools you think I should include but aren’t on the list yet!
Disclaimer
- This list was made in November 2019, and the market must have changed in the last 6 months.
- Some tech companies just have a set of tools so large that I can’t enumerate them all. For example, Amazon Web Services offer over 165 fully featured services.
- There are many stealth startups that I’m not aware of, and many that died before I heard of them.
This post consists of 6 parts:
I. Overview
II. The landscape over time
III. The landscape is under-developed
IV. Problems facing MLOps
V. Open source and open-core
VI. Conclusion
I. Overview
In one way to generalize the ML production flow that I agreed with, it consists of 4 steps:
- Project setup
- Data pipeline
- Modeling & training
- Serving
I categorize the tools based on which step of the workflow that it supports. I don’t include Project setup since it requires project management tools, not ML tools. This isn’t always straightforward since one tool might help with more than one step. Their ambiguous descriptions don’t make it any easier: “we push the limits of data science”, “transforming AI projects into real-world business outcomes”, “allows data to move freely, like the air you breathe”, and my personal favorite: “we lived and breathed data science”.
I put the tools that cover more than one step of the pipeline into the category that they are best known for. If they’re known for multiple categories, I put them in the All-in-one category. I also include the Infrastructure category to include companies that provide infrastructure for training and storage. Most of these are Cloud providers.
II. The landscape over time
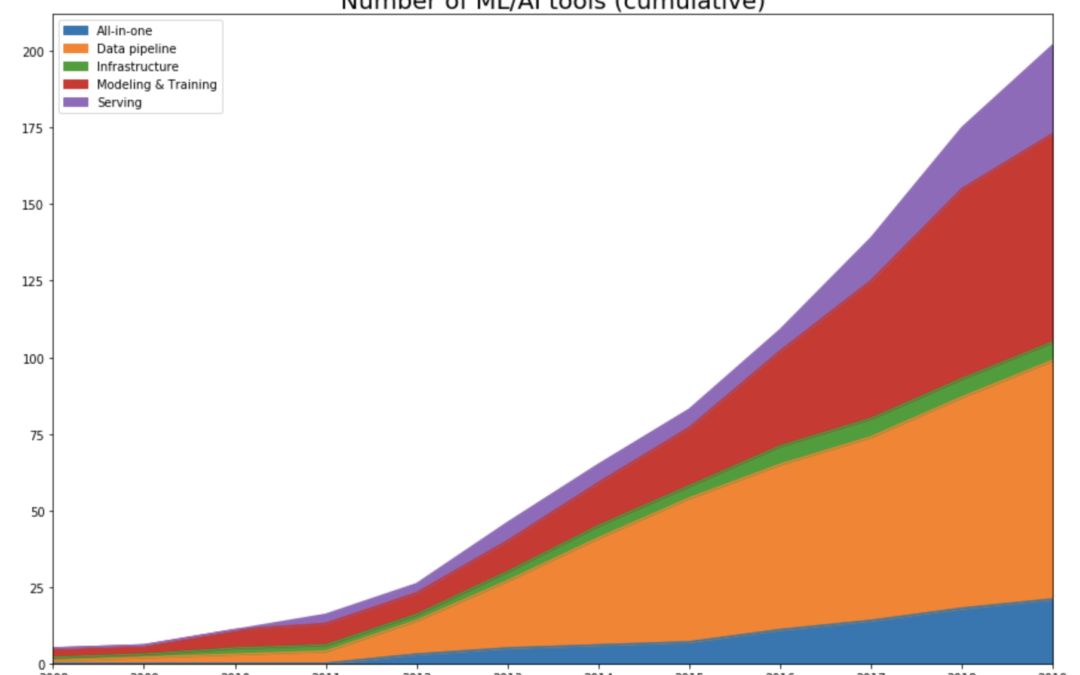
I tracked the year each tool was launched. If it’s an open-source project, I looked at the first commit to see when the project began its public appearance. If it’s a company, I looked at the year it started on Crunchbase. Then I plotted the number of tools in each category over time.
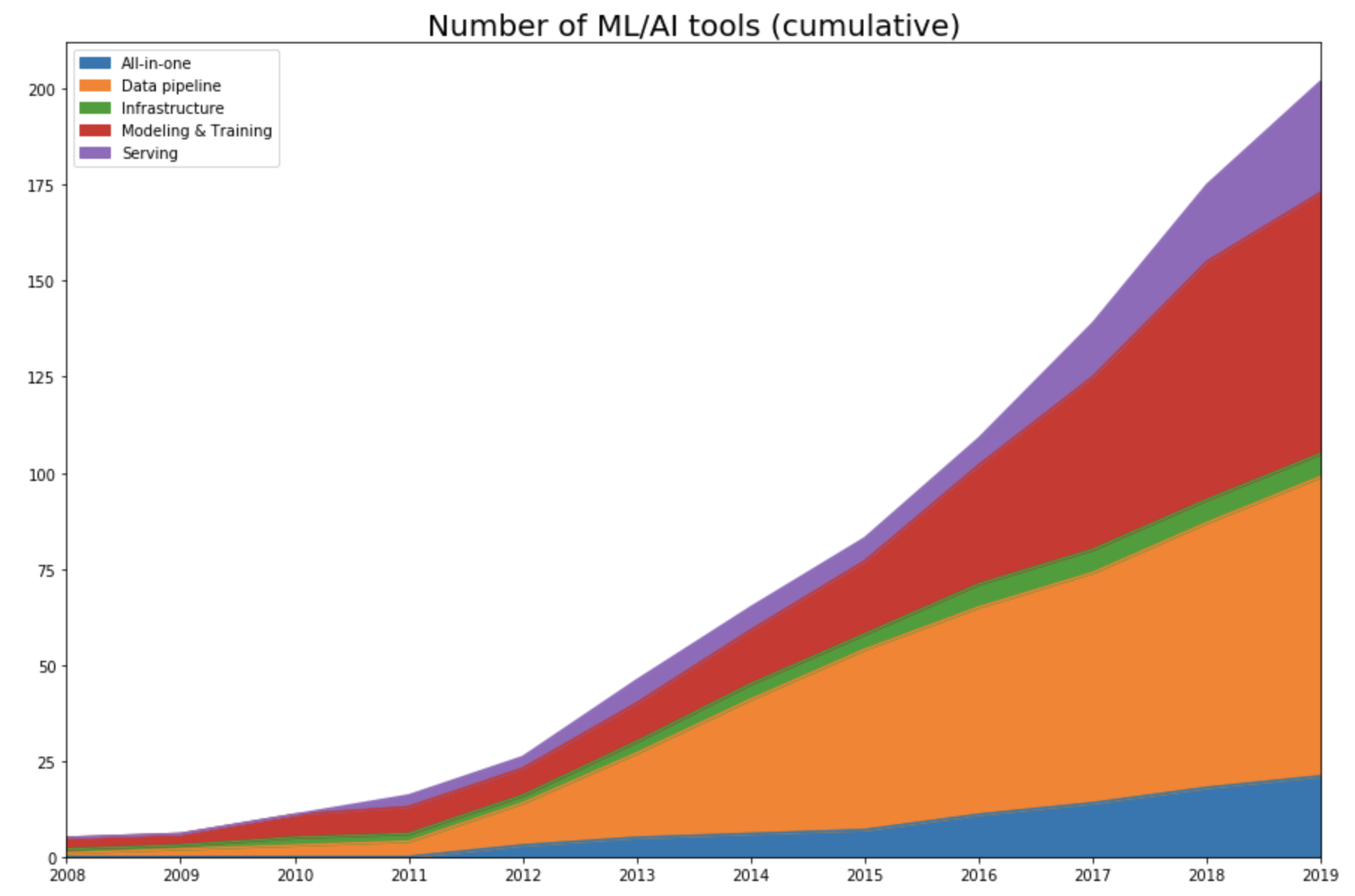
As expected, this data shows that the space only started exploding in 2012 with the renewed interest in deep learning.
Pre-AlexNet (pre-2012)
Up until 2011, the space is dominated by tools for modeling and training, with some frameworks that either are still very popular (e.g. scikit-learn) or left influence on current frameworks (Theano). A few ML tools that started pre-2012 and survived until today have either had their IPOs (Cloudera, Datadog, Alteryx), been acquired (Figure Eight), or become popular open-source projects actively developed by the community (Spark, Flink, Kafka).
Development phase (2012-2015)
As the machine learning community took the “let’s throw data at it” approach, the ML space became the data space. This is even more clear when we look into the number of tools started each year in each category. In 2015, 57% (47 out of 82 tools) are data pipeline tools.
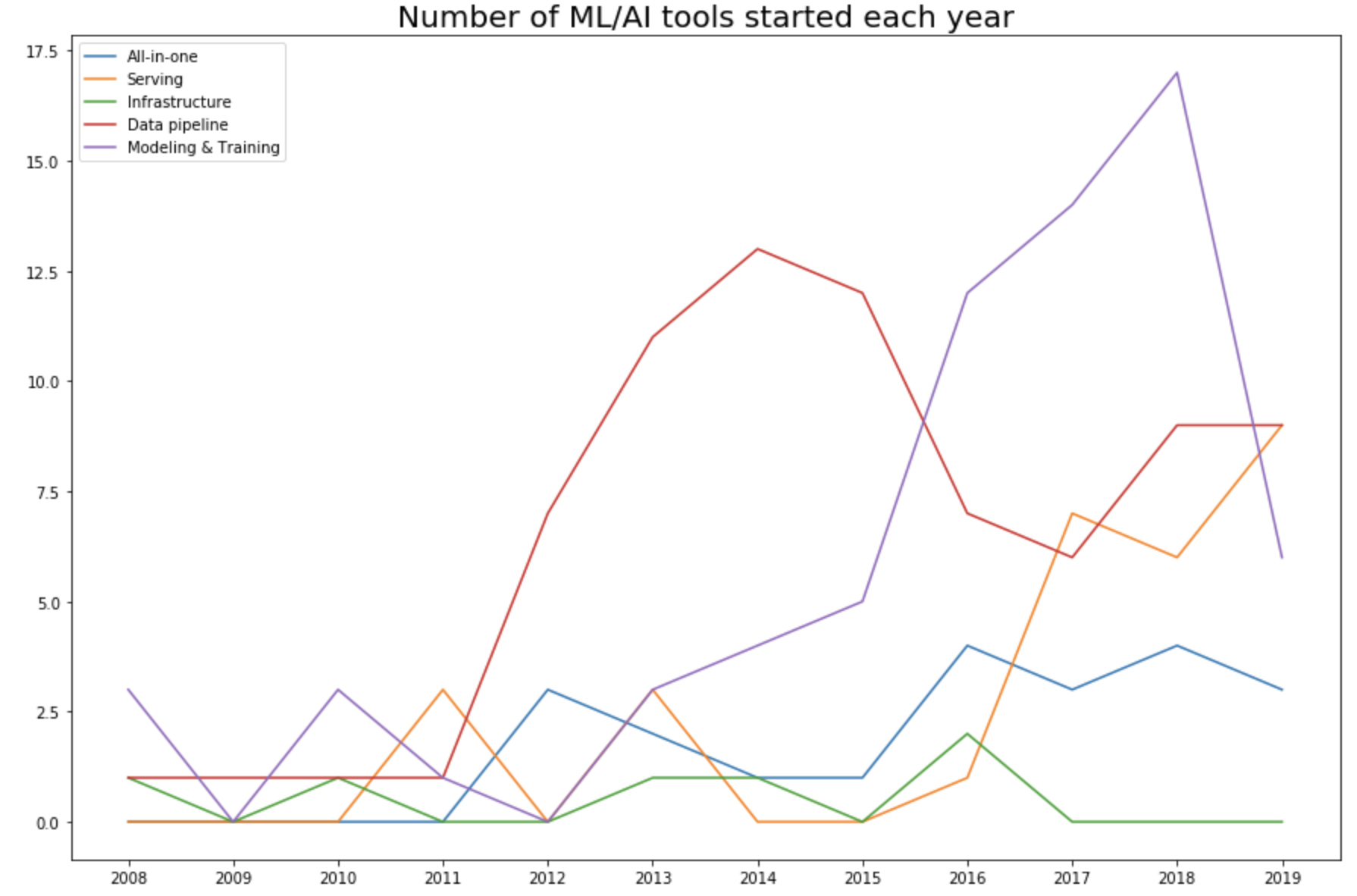
Production phase (2016-now)
While it’s important to pursue pure research, most companies can’t afford it unless it leads to short-term business applications. As ML research, data, and off-the-shelf models become more accessible, more people and organizations would want to find applications for them, which increases the demand for tools to help productionize machine learning.
In 2016, Google announced its use of neural machine translation to improve Google Translate, marking the one of the first major applications of deep learning in the real world. Since then, many tools have been developed to facilitate serving ML applications.
III. The landscape is under-developed
While there are many AI startups, most of them are application startups (providing applications such as business analytics or customer support) instead of tooling startups (creating tools to help other companies build their own applications). Or in VC terms, most startups are vertical AI. Among Forbes 50 AI startups in 2019, only 7 companies are tooling companies.
Applications are easier to sell, since you can go to a company and say: “We can automate half of your customer support effort.” Tools take longer to sell but can have a larger impact since you’re not targeting a single application but a part of the ecosystem. Many companies can coexist providing the same application, but for a part of the process, usually a selected few tools can coexist.
After extensive search, I could only find ~200 AI tools, which is puny compared to the number of traditional software engineering tools. If you want testing for traditional Python application development, you can find at least 20 tools within 2 minutes of googling. If you want testing for machine learning models, there’s none.
IV. Problems facing MLOps
Many traditional software engineering tools can be used to develop and serve machine learning applications. However, many challenges are unique to ML applications and require their own tools.
In traditional SWE, coding is the hard part, whereas in ML, coding is a small part of the battle. Developing a new model that can provide significant performance improvements in real world tasks is very hard and very costly. Most companies won’t focus on developing ML models but will use an off-the-shelf model, e.g. “if you want it put a BERT on it.”
For ML, applications developed with the most/best data win. Instead of focusing on improving deep learning algorithms, most companies will focus on improving their data. Because data can change quickly, ML applications need faster development and deployment cycles. In many cases, you might have to deploy a new model every night.
The size of ML algorithms is also a problem. The pretrained large BERT model has 340M parameters and is 1.35GB. Even if it can fit on a consumer device (e.g. your phone), the time it takes for BERT to run inference on a new sample makes it useless for many real world applications. For example, an autocompletion model is useless if the time it takes to suggest the next character is longer than the time it takes for you to type.
Git does versioning by comparing differences line by line and therefore works well for most traditional software engineering programs. However, it’s not suitable for versioning datasets or model checkpoints. Pandas works well for most traditional dataframe manipulation, but doesn’t work on GPUs.
Row-based data formats like CSV work well for applications using less data. However, if your samples have many features and you only want to use a subset of them, using row-based data formats still requires you to load all features. Columnar file formats like PARQUET and OCR are optimized for that use case.
Some of the problems facing ML applications development:
- Model compression: How to compress an ML model to fit in consumer devices? Example: Xnor.ai, a startup spun out of Allen Institute to focus on model compression, raised $14.6M at the valuation of $62M in May 2018. In January 2020, Apple bought it for ~$200M and shut down its website.
I plotted the number of tools by the main problems they address.
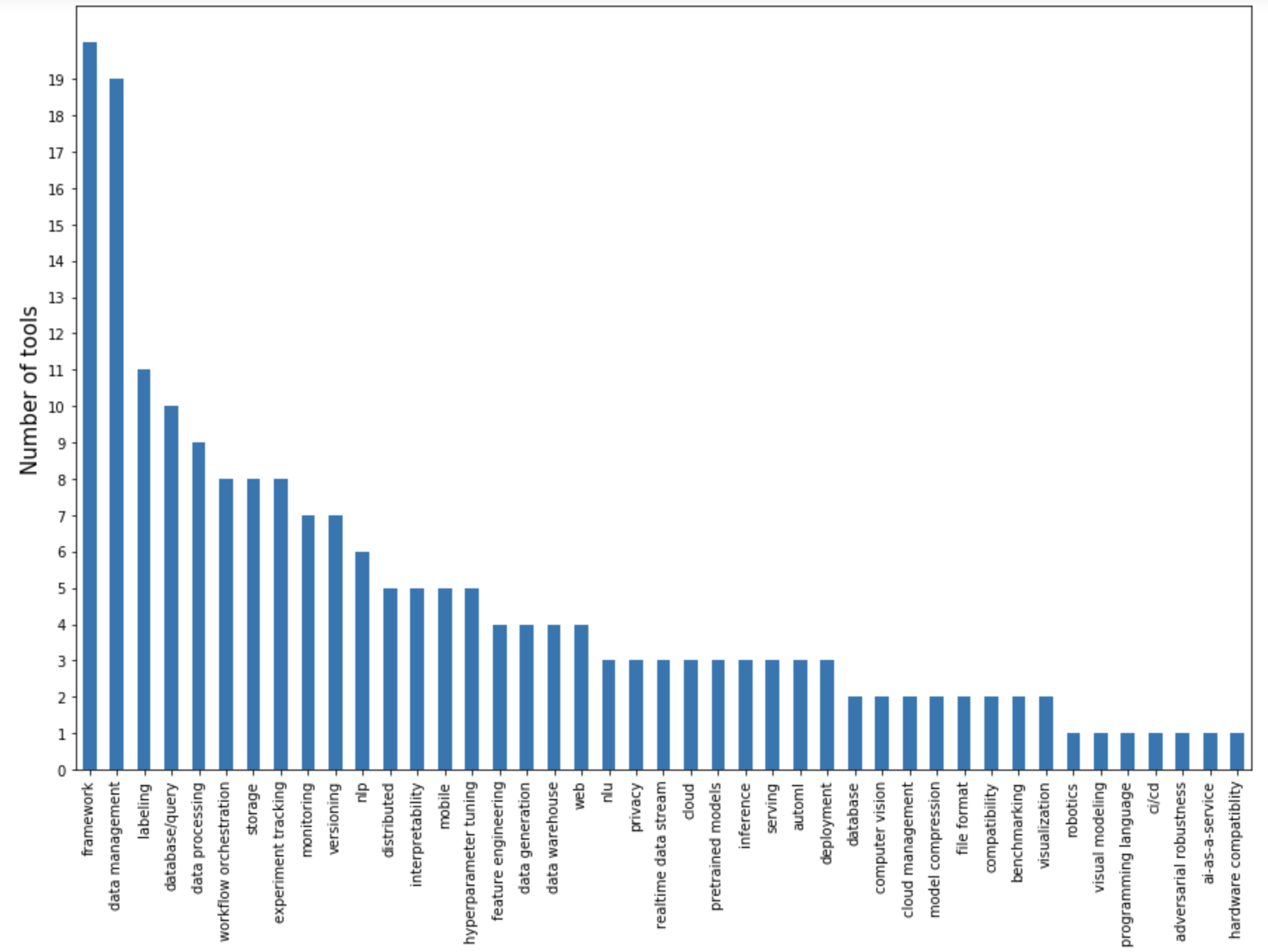
A large portion focuses on the data pipeline: data management, labeling, database/query, data processing, data generation. Data pipeline tools are also likely to aim to be all-in-one platforms. Because data handling is the most resource-intensive phase of a project, once you’ve had people put their data on your platform, it’s tempting to provide them with a couple of pre-built/pre-trained models.
Tools for modeling & training are mostly frameworks. The deep learning frameworks competition cooled down to be mostly between PyTorch and TensorFlow, and higher-level frameworks that wrap around these two for specific families of tasks such as NLP, NLU, and multimodal problems. There are frameworks for distributed training. There’s also this new framework coming out of Google that every Googler who hates TensorFlow has been raving about: JAX.
There are standalone tools for experiment tracking, and popular frameworks also have their own experiment tracking features built-in. Hyperparameter tuning is important and it’s not surprising to find several that focus on it, but none seems to catch on because the bottleneck for hyperparameter tuning is not the setup, but the computing power needed to run it.
The most exciting problems yet to be solved are in the deployment and serving space. One reason for the lack of serving solutions is the lack of communication between researchers and production engineers. At companies that can afford to pursue AI research (e.g. big companies), the research team is separated from the deployment team, and the two teams only communicate via the p-managers: product managers, program managers, project managers. Small companies, whose employees can see the entire stack, are constrained by their immediate product needs. Only a few startups, usually those founded by accomplished researchers with enough funding to hire accomplished engineers, have managed to bridge the gap. These startups are poised to take a big chunk of the AI tooling market.
V. Open-source and open-core
109 out of 202 tools I looked at are OSS. Even tools that aren’t open-source are usually accompanied by open-source tools.
There are several reasons for OSS. One is the reason that all pro-OSS people have been talking about for years: transparency, collaboration, flexibility, and it just seems like the moral thing to do. Clients might not want to use a new tool without being able to see its source code. Otherwise, if that tool gets shut down – which happens a lot with startups – they’ll have to rewrite their code.
OSS means neither non-profit nor free. OSS maintenance is time-consuming and expensive. The size of the TensorFlow team is rumored to be close to 1000. Companies don’t offer OSS tools without business objectives in mind, e.g. if more people use their OSS tools, more people know about them, trust their technical expertise, and might buy their proprietary tools and want to join their teams.
Google might want to popularize their tools so that people use their cloud services. NVIDIA maintains cuDF (and previously dask) so that they can sell more GPUs. Databricks offers MLflow for free but sells their data analytics platform. Netflix started their dedicated machine learning team very recently, and released their Metaflow framework to put their name on the ML map to attract talents. Explosion offers SpaCy for free but charges for Prodigy. HuggingFace offers transformers for free and I have no idea how they make money.
Since OSS has become a standard, it’s challenging for startups to figure out a business model that works. Any tooling company started has to compete with existing open-source tools. If you follow the open-core business model, you have to decide which features to include in the OSS, which to include in the paid version without appearing greedy, or how to get free users to start paying.
VI. Conclusion
There has been a lot of talk on whether the AI bubble will burst. A large portion of AI investment is in self-driving cars, and as fully autonomous vehicles are still far from being a commodity, some hypothesize that investors will lose hope in AI altogether. Google has freezed hiring for ML researchers. Uber laid off the research half of their AI team. Both decisions were made pre-covid. There’s rumor that due to a large number of people taking ML courses, there will be far more people with ML skills than ML jobs.
Is it still a good time to get into ML? I believe that the AI hype is real and at some point, it has to calm down. That point might have already happened. However, I don’t believe that ML will disappear. There might be fewer companies that can afford to do ML research, but there will be no shortage of companies that need tooling to bring ML into their production.
If you have to choose between engineering and ML, choose engineering. It’s easier for great engineers to pick up ML knowledge, but it’s a lot harder for ML experts to become great engineers. If you become an engineer who builds great tools for ML, I’d forever be in your debt.
Acknowledgment: Thanks Andrey Kurenkov for being the most generous editor one could ask for. Thanks Luke Metz for being a wonderful first reader.
This content was originally published here.
